A Hazard Based Approach to User Return Time Prediction
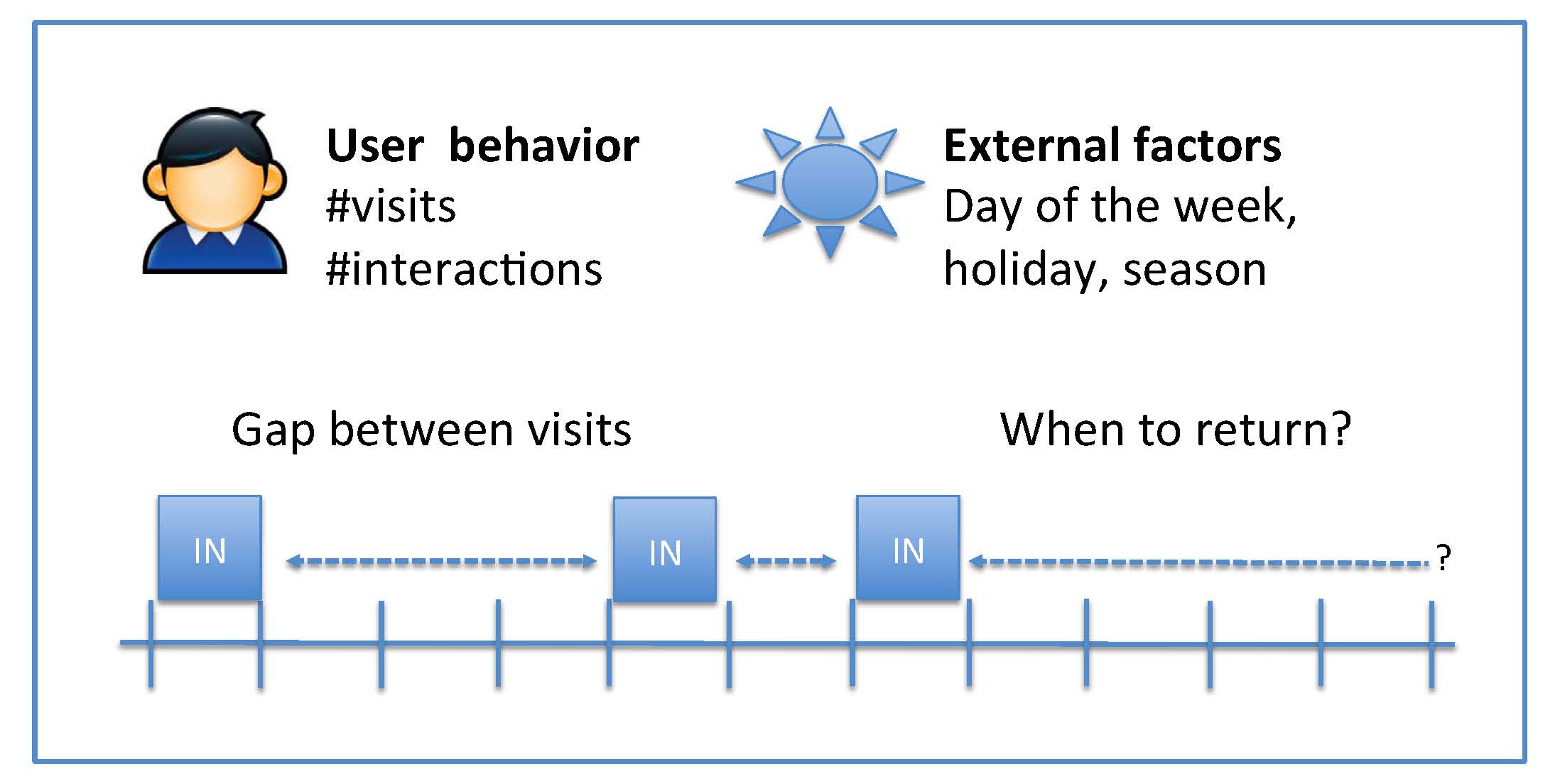
Abstract: In the competitive environment of the internet, retaining and growing one's user base is of major concern to most web services. In this work, we address this problem by proposing a new retention metric for web services by concentrating on the rate of user return. Our solution is based on the Cox's proportional hazard model from survival analysis.
Learning Multiple-question Decision Trees for Cold-start Recommendation
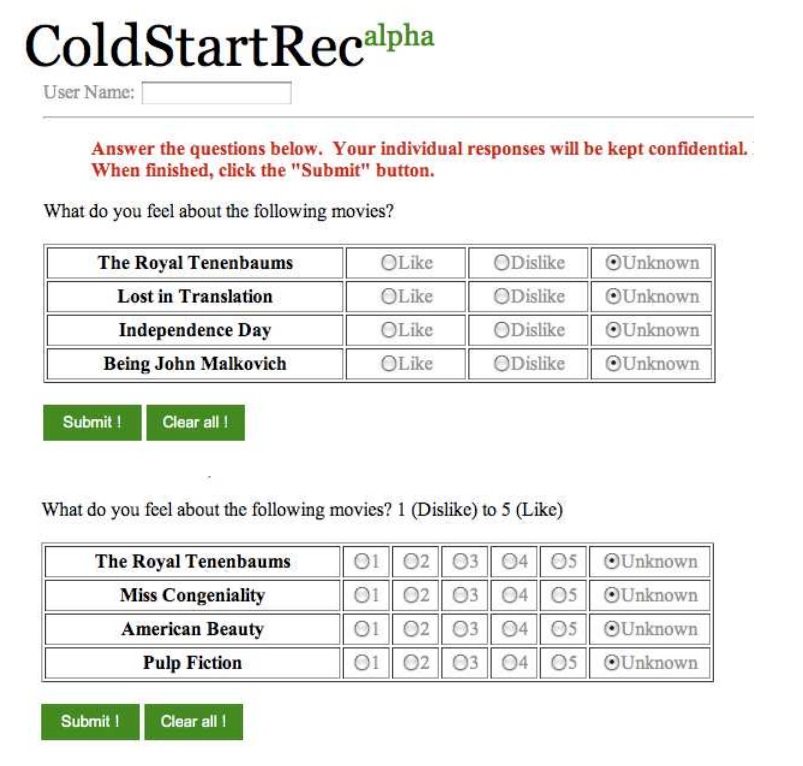
Abstract: For cold-start recommendation, it is important to rapidly profile new users and generate a good initial set of recommendations through an interview process. In this project, we propose an algorithm learning to conduct the interview process guided by a decision tree with multiple questions at each split. Both quantitative experiment and user study indicate that the proposed algorithm outperforms state-of-the-art approaches in terms of both the prediction accuracy and user cognitive efforts.
Automatic Feature Induction for Stagewise Collaborative Filtering
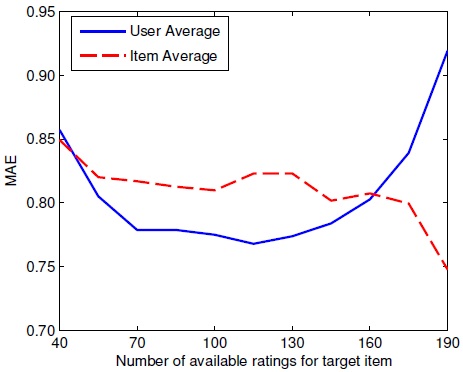
Abstract: For the task of predicting missing ratings in collaborative filtering, we observe that different models have relative advantages in different regions of the input space. This motivates our approach of using stagewise linear combinations of collaborative filtering algorithms, with non-constant combination coefficients based on kernel smoothing. The resulting stagewise model is computationally scalable and outperforms a wide selection of state-of-the-art collaborative filtering algorithms.
PREA: Personalized Recommendation Algorithm Toolkit
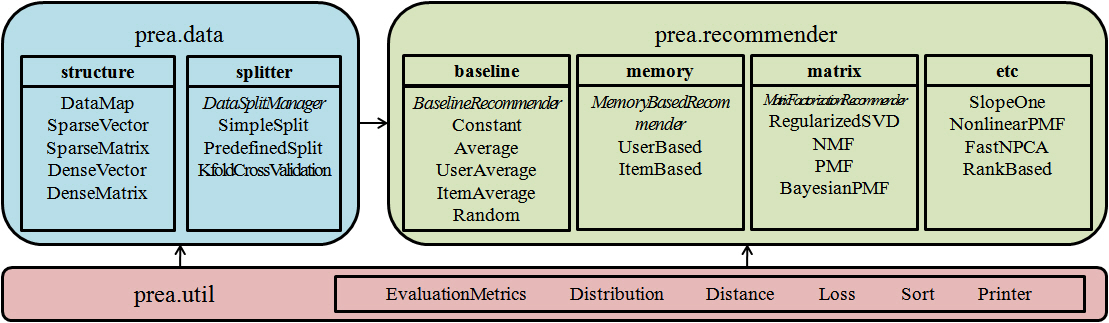
Abstract: With increase demand of personalized services in e-commerce, recommendation systems are playing a critical role in commercial websites. In academia, many researchers have tried to achieve better performance and accuracy with various algorithms. PREA is an open source Java software implementing recent state-of-the-art recommendation algorithms as well as popular evaluation metrics.
Modeling Rankings in Recommendation Systems
Abstract: Modeling ranked data is an essential component in a number of important applications including recommendation systems and web-search. In many cases, judges omit preference among unobserved items and between unobserved and observed items. This case of analyzing incomplete rankings is very important from a practical perspective and yet has not been fully studied due to considerable computational difficulties. We show how to avoid such computational difficulties and efficiently construct a non-parametric model for rankings with missing items. We demonstrate our approach and show how it applies to real world data in the context of collaborative filtering.
Journal of the Royal Statistical Society, Series C, 61(3):471-492, May 2012 Full paper (PDF)
Visualizing Search Algorithm Dissimilarites
Abstract: We introduce a new dissimilarity function for ranked lists, the expected weighted Hoeffding distance, that has several advantages over current dissimilarity measures for partial rankings: it is (i) symmetric, (ii) interpretable with respect to search algorithms retrieving ranked lists of different lengths, (iii) flexible enough to model the increased attention users pay to top ranks over bottom ranks, (iv) computationally efficient, and (v) aggregate information over multiple queries in a meaningful way. We then use the measure with multi-dimensional scaling to visualize and explore relationships between the different search engines. Such visualization is highly effective for obtaining insights on which search engines to use, what search strategies users can employ, and how search results evolve over time.
The Nineteenth International World Wide Web Conference (WWW), 2010 Full paper (PDF)